Tout le monde connaît les critères de divisibilité par 2, par 3, par 4, par 5 ou par 6. Je vous les rappelle : un nombre est divisible par
- 2 si son dernier chiffre est 0, 2, 4, 6 ou 8
- 3 si la somme de ses chiffres est elle-même divisible par 3
- 4 si ses deux derniers chiffres forment un nombre divisible par 4
- 5 s’il se termine par 0 ou 5
- 6 s’il est divisible par 2 et par 3
Cependant, si on demande de dire si un nombre est divisible par 7, je ne suis pas sûr que tout le monde sache répondre. En Novembre 2019, un jeune Nigérian vivant au Royaume-Uni du nom de Chika Ofili a reçu un « TruLittleHero Awards » pour avoir découvert un critère de divisibilité par 7. Voici l’énoncé du test de Chika (comme il l’a nommé) pour lequel il a été récompensé:
Un nombre est divisible par 7 si, et seulement si, la somme de son nombre de dizaines et de 5 fois son nombre des unités est divisible par 7.
Même si ce critère n’était en fait pas du tout nouveau et qu’il était déjà connu depuis longtemps, c’est une belle performance pour un jeune de cet âge de l’avoir trouvé.

Le test de Chika permet en particulier de savoir si les Sept nains sont bien au complet.
Un exemple
Voyons comment utiliser ce critère pour déterminer si 651 est divisible par 7. Le nombre de dizaines est 65 et le nombre des unités est 1. On calcule:

Comme 70 est un multiple de 7, il en va de même pour 651 qui est donc divisible par 7. Bien entendu, on peut répéter cette opération si l’on tombe sur un nombre dont on ne voit pas tout de suite qu’il est divisible par 7. Par exemple, pour savoir si 4826 est divisible par 7, on calcule successivement:
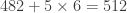
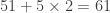
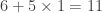
Comme 11 n’est pas divisible par 7, 4826 non plus n’est pas divisible par 7. Facile, non ?
Une démonstration
Ce critère ayant quand même été parachuté brutalement, il serait de bon ton de le démontrer afin de comprendre pourquoi il marche et, pour cela, nous allons utiliser le très élégant langage des congruences inventé par Gauss. On considère un nombre  dont le nombre de dizaines est
dont le nombre de dizaines est  et le nombre d’unités est
et le nombre d’unités est  . Autrement dit,
. Autrement dit, 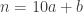 .
.
• Si est divisible par 7, alors ![n \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=n+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) donc
donc
![10a+b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=10a%2Bb+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
En multipliant les deux membres par 5, on obtient:
![50a + 5b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=50a+%2B+5b+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Comme ![50 \equiv 1 \mod[7]](https://s0.wp.com/latex.php?latex=50+%5Cequiv+1+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) (car
(car 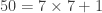 ) alors
) alors
![a + 5b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=a+%2B+5b+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
ce qui montre que la somme du nombre de dizaines et de 5 fois le nombre des unités est divisible par 7.
• Réciproquement, si 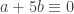 alors en multipliant par 10 de chaque côté,
alors en multipliant par 10 de chaque côté,
![10a+50b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=10a%2B50b+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
d’où
ce qui veut bien dire que 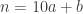 est divisible par 7.
est divisible par 7.
Analyse de la démonstration
Le point clé de cette démonstration est d’avoir multiplié les deux membres par 5 pour le sens direct et par 10 pour la réciproque. Les nombres 5 et 10 ne sont pas là par hasard et un lien les unis modulo 7 : le nombre 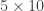 est un multiple de 7 augmenté de 1, c’est-à-dire que
est un multiple de 7 augmenté de 1, c’est-à-dire que ![5 \times 10 \equiv 1 \mod[7]](https://s0.wp.com/latex.php?latex=5+%5Ctimes+10+%5Cequiv+1+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) . On dit aussi que 5 est inversible modulo 7 et que « son » inverse est 10 (et, inversement si je puis dire, le nombre 10 est inversible modulo 7 et « son » inverse est 5).
. On dit aussi que 5 est inversible modulo 7 et que « son » inverse est 10 (et, inversement si je puis dire, le nombre 10 est inversible modulo 7 et « son » inverse est 5).
Il se trouve qu’il existe d’autres nombres qui sont inversibles modulo 7 (en fait, tous sauf les multiples de 7 mais c’est une autre histoire). Si nous prenons par exemple le nombre 4, dont l’inverse modulo 7 est 2 (car ![4 \times 2 \equiv 1 \mod[7]](https://s0.wp.com/latex.php?latex=4+%5Ctimes+2+%5Cequiv+1+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) alors, en reprenant la démonstration précédente, mais en multipliant par 4, on a
) alors, en reprenant la démonstration précédente, mais en multipliant par 4, on a
![10a +b \equiv 0 \mod[7] \Longrightarrow 40a + 4b \equiv 0 \mod[7] \Longrightarrow 5a + 4b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=10a+%2Bb+%5Cequiv+0+%5Cmod%5B7%5D+%5CLongrightarrow+40a+%2B+4b+%5Cequiv+0+%5Cmod%5B7%5D+%5CLongrightarrow+5a+%2B+4b+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
car ![40 \equiv 5 \mod[7]](https://s0.wp.com/latex.php?latex=40+%5Cequiv+5+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Réciproquement, en multipliant par 2,
. Réciproquement, en multipliant par 2,
![5a+4b \equiv 0 \mod[7] \Longrightarrow 10a + 8b \equiv 0 \mod[7] \Longrightarrow 10a + b \equiv 0 \mod[7]](https://s0.wp.com/latex.php?latex=5a%2B4b+%5Cequiv+0+%5Cmod%5B7%5D+%5CLongrightarrow+10a+%2B+8b+%5Cequiv+0+%5Cmod%5B7%5D+%5CLongrightarrow+10a+%2B+b+%5Cequiv+0+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002)
car ![8 \equiv 1 \mod[7]](https://s0.wp.com/latex.php?latex=8+%5Cequiv+1+%5Cmod%5B7%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Nous venons donc fièrement de fabriquer un nouveau critère de divisibilité qui est le suivant:
. Nous venons donc fièrement de fabriquer un nouveau critère de divisibilité qui est le suivant:
Un nombre est divisible par 7 si, et seulement si, la somme de 5 fois son nombre de dizaines et de 4 fois son nombre des unités est divisible par 7.
Par exemple, pour voir que 105 est bien divisible par 7, il suffit de voir que 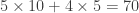 est lui-même divisible par 7. Nous méritons aussi notre récompense !
est lui-même divisible par 7. Nous méritons aussi notre récompense !
Des critères de divisibilité pour d’autres nombres
Les critères de divisibilité par 7, c’est bien (quoique vous n’auriez peut-être pas dit cela avant de lire cet article) mais les triskaïdékaphobes veulent eux savoir si les nombres qu’ils manipulent sont des multiples de 13. Et bien, je leur dis de prendre un nombre inversible modulo 13 et de faire leur propre critère. Par exemple, si on prend le nombre 2 (qui est bien inversible modulo 13 car  ) alors
) alors
![2 \times (10a + b) = 20a + 2b \equiv 7a + 2b \mod[13]](https://s0.wp.com/latex.php?latex=2+%5Ctimes+%2810a+%2B+b%29+%3D+20a+%2B+2b+%5Cequiv+7a+%2B+2b+%5Cmod%5B13%5D&bg=ffffff&fg=333333&s=0&c=20201002)
On en déduit le critère de divisibilité par 13 suivant:
Un nombre est divisible par 13 si, et seulement si, la somme de 7 fois son nombre de dizaines et de 2 fois son nombre des unités est divisible par 13.
Des critères plus simples
Vous avez probablement dû vous insurger en lisant le critère précédent (sinon, vous devriez). Multiplier un nombre de dizaines par 7 n’est clairement pas chose aisée de tête. Tous ces critères que l’on peut créer ne se valent donc pas tous, et ceux pour lesquels on doit multiplier le nombre de dizaines par un nombre supérieur ou égal à 2 sont évidemment moins pratiques. L’idéal est donc d’avoir un critère où il n’y a pas besoin de multiplier le nombre de dizaines, comme dans le critère énoncé par le jeune Chika. Reprenons donc le nombre 13 et trouvons en un critère de divisibilité plus simple.
Si l’on en croit les démonstrations précédentes, cela revient donc à trouver un nombre  tel que
tel que ![k \times 10 \equiv 1 \mod[13]](https://s0.wp.com/latex.php?latex=k+%5Ctimes+10+%5Cequiv+1+%5Cmod%5B13%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Autrement dit, il s’agit de trouver un inverse de 10 modulo 13.
. Autrement dit, il s’agit de trouver un inverse de 10 modulo 13.
Pour cela, on peut utiliser un algorithme bien connu qu’on nomme l’algorithme d’Euclide étendu (que je ne détaillerai pas ici… mais il existe des calculateurs en ligne). Sachant que 4 est un inverse de 10 modulo 13, en mutlipliant 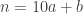 par 4, il vient
par 4, il vient
![10a + b \equiv 0 \mod[13] \Longrightarrow 40a + 4b \equiv 0 \mod[13] \Longrightarrow a + 4b \equiv 0 \mod[13]](https://s0.wp.com/latex.php?latex=10a+%2B+b+%5Cequiv+0+%5Cmod%5B13%5D+%5CLongrightarrow+40a+%2B+4b+%5Cequiv+0+%5Cmod%5B13%5D+%5CLongrightarrow+a+%2B+4b+%5Cequiv+0+%5Cmod%5B13%5D&bg=ffffff&fg=333333&s=0&c=20201002)
La réciproque étant aussi vraie, on en déduit alors le critère de divisibilité par 13 suivant:
Un nombre est divisible par 13 si, et seulement si, la somme de son nombre de dizaines et de 4 fois son nombre des unités est divisible par 13.
Généralisation
Vous l’aurez compris, pour obtenir un critère de divisibilité simple par un nombre  donné, il suffit de trouver un inverse de 10 modulo . Par exemple, comme un inverse de 10 modulo
donné, il suffit de trouver un inverse de 10 modulo . Par exemple, comme un inverse de 10 modulo 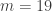 est 2, alors un nombre sera divisible par 19 si, et seulement si, la somme de son nombre de dizaines et de 2 fois son nombre des unités est divisible par 19.
est 2, alors un nombre sera divisible par 19 si, et seulement si, la somme de son nombre de dizaines et de 2 fois son nombre des unités est divisible par 19.
Une dernière question se pose alors: que se passe-t-il si 10 ne possède pas d’inverse modulo ? Par exemple, si 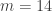 ou
ou 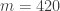 , un tel inverse de 10 n’existe pas (on peut en fait montrer qu’un inverse existe si, et seulement si, 10 et sont premiers entre eux c’est-à-dire si, et seulement si, n’est divisible ni par 2, ni par 5). Dans ce cas, il faut se ramener à d’autres nombres, un peu comme pour savoir si un nombre est divisible par 6 il faut et il suffit qu’il soit divisible par 2 et 3.
, un tel inverse de 10 n’existe pas (on peut en fait montrer qu’un inverse existe si, et seulement si, 10 et sont premiers entre eux c’est-à-dire si, et seulement si, n’est divisible ni par 2, ni par 5). Dans ce cas, il faut se ramener à d’autres nombres, un peu comme pour savoir si un nombre est divisible par 6 il faut et il suffit qu’il soit divisible par 2 et 3.
Prenons le cas de : comme les plus grandes puissances de 2 et de 5 divisant 420 sont 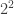 et
et 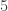 et que
et que  , il suffit alors de connaitre un critère de divisibilité par 4, par 5 et par 21. Vous connaissez déjà des critères de divisibilité par 4 et 5, et vous venez d’apprendre comment créer un critère de divisibilité par 21 donc vous pouvez facilement savoir si un nombre est divisible par 420. Mieux encore: comme
, il suffit alors de connaitre un critère de divisibilité par 4, par 5 et par 21. Vous connaissez déjà des critères de divisibilité par 4 et 5, et vous venez d’apprendre comment créer un critère de divisibilité par 21 donc vous pouvez facilement savoir si un nombre est divisible par 420. Mieux encore: comme 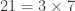 , il suffit en fait de connaître un critère de divisibilité par 3 et par 7.
, il suffit en fait de connaître un critère de divisibilité par 3 et par 7.
Plus généralement, pour obtenir un critère de divisibilité par un nombre quelconque, il suffit de connaître des critères de divisibilité par  et par
et par  mais aussi de fabriquer des critères de divisibilité par
mais aussi de fabriquer des critères de divisibilité par 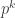 où
où  est un nombre premier différent de 2 et de 5. Et ça, vous savez le faire maintenant.
est un nombre premier différent de 2 et de 5. Et ça, vous savez le faire maintenant.
Notes:

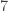
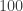

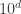
![a^{\varphi(n)} \equiv 1 \mod[n]](https://s0.wp.com/latex.php?latex=a%5E%7B%5Cvarphi%28n%29%7D+%5Cequiv+1+%5Cmod%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
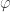
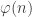

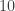
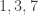
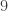
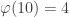

![3^{\varphi(10)} \equiv 1 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B%5Cvarphi%2810%29%7D+%5Cequiv+1+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^{4} \equiv 1 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B4%7D+%5Cequiv+1+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
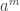
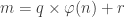
![a^{m} = a^{ q \times \varphi(n) + r} = \left(a^{\varphi(n)} \right)^q \times a^r \equiv 1^q \times a^r = a^r \mod[n]](https://s0.wp.com/latex.php?latex=a%5E%7Bm%7D+%3D+a%5E%7B+q+%5Ctimes+%5Cvarphi%28n%29+%2B+r%7D+%3D+%5Cleft%28a%5E%7B%5Cvarphi%28n%29%7D+%5Cright%29%5Eq+%5Ctimes+a%5Er+%5Cequiv+1%5Eq+%5Ctimes+a%5Er+%3D+a%5Er+%5Cmod%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\boxed{a^m \equiv a^{m \mod [\varphi(n)]} \mod[n]}](https://s0.wp.com/latex.php?latex=%5Cboxed%7Ba%5Em+%5Cequiv+a%5E%7Bm+%5Cmod+%5B%5Cvarphi%28n%29%5D%7D+%5Cmod%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![m \mod[\varphi(n)]](https://s0.wp.com/latex.php?latex=m+%5Cmod%5B%5Cvarphi%28n%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
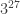
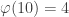
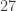
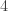
![27 \mod[4] = 3](https://s0.wp.com/latex.php?latex=27+%5Cmod%5B4%5D+%3D+3&bg=ffffff&fg=333333&s=0&c=20201002)
![3^{27} \equiv 3^{27 \mod[4]} = 3^{3} = 27 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B27%7D+%5Cequiv+3%5E%7B27+%5Cmod%5B4%5D%7D+%3D+3%5E%7B3%7D+%3D+27+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![a^{b^{c}} \mod[n]](https://s0.wp.com/latex.php?latex=a%5E%7Bb%5E%7Bc%7D%7D+%5Cmod%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![a^{(b \mod \varphi(n))^{c \mod[\varphi(\varphi(n}))]} \mod [n]](https://s0.wp.com/latex.php?latex=a%5E%7B%28b+%5Cmod+%5Cvarphi%28n%29%29%5E%7Bc+%5Cmod%5B%5Cvarphi%28%5Cvarphi%28n%7D%29%29%5D%7D+%5Cmod+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![3^{3^3} \equiv 3^{(3 \mod \varphi(10))^{3 \mod[\varphi(\varphi(10}))]} \mod [10]](https://s0.wp.com/latex.php?latex=3%5E%7B3%5E3%7D+%5Cequiv+3%5E%7B%283+%5Cmod+%5Cvarphi%2810%29%29%5E%7B3+%5Cmod%5B%5Cvarphi%28%5Cvarphi%2810%7D%29%29%5D%7D+%5Cmod+%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
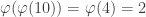
![3^{3^3} \equiv 3^{(3 \mod[4])^{3 \mod[2]}} = 3^{3^{1}} = 3^3 = 27 \equiv 7 \mod [10]](https://s0.wp.com/latex.php?latex=3%5E%7B3%5E3%7D+%5Cequiv+3%5E%7B%283+%5Cmod%5B4%5D%29%5E%7B3+%5Cmod%5B2%5D%7D%7D+%3D+3%5E%7B3%5E%7B1%7D%7D+%3D+3%5E3+%3D+27+%5Cequiv+7+%5Cmod+%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
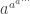
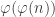
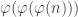
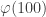
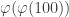

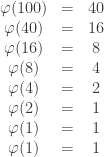
![3^{(3 \mod[40])^{(3 \mod[16])^{\cdots}} } \mod[100]](https://s0.wp.com/latex.php?latex=3%5E%7B%283+%5Cmod%5B40%5D%29%5E%7B%283+%5Cmod%5B16%5D%29%5E%7B%5Ccdots%7D%7D+%7D+%5Cmod%5B100%5D&bg=ffffff&fg=333333&s=0&c=20201002)


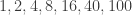
![3\mod [1] = 0](https://s0.wp.com/latex.php?latex=3%5Cmod+%5B1%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
![(3 \mod [2])^0 = 1^0 = 1](https://s0.wp.com/latex.php?latex=%283%C2%A0+%5Cmod+%5B2%5D%29%5E0+%3D+1%5E0+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)
![(3 \mod [4])^1 = 3^1 = 3](https://s0.wp.com/latex.php?latex=%283+%5Cmod+%5B4%5D%29%5E1+%3D+3%5E1+%3D+3&bg=ffffff&fg=333333&s=0&c=20201002)
![(3 \mod [8])^3 = (3^3 \mod [8]) = 27 \mod [8] = 3](https://s0.wp.com/latex.php?latex=%283%C2%A0+%5Cmod+%5B8%5D%29%5E3+%3D+%283%5E3+%5Cmod+%5B8%5D%29+%3D+27+%5Cmod+%5B8%5D+%3D+3&bg=ffffff&fg=333333&s=0&c=20201002)
![(3\mod [16])^3 = 3^3 = 27](https://s0.wp.com/latex.php?latex=%283%5Cmod+%5B16%5D%29%5E3+%3D+3%5E3+%3D+27&bg=ffffff&fg=333333&s=0&c=20201002)
![(3 \mod [40])^{27} = 3^{27} \mod[40] = 7625597484987 \mod [40] = 27](https://s0.wp.com/latex.php?latex=%283+%5Cmod+%5B40%5D%29%5E%7B27%7D+%3D+3%5E%7B27%7D+%5Cmod%5B40%5D+%3D+7625597484987+%5Cmod+%5B40%5D+%3D+27&bg=ffffff&fg=333333&s=0&c=20201002)
![(3 \mod [100])^{27} = 3^{27} \mod [100] = 87](https://s0.wp.com/latex.php?latex=%283+%5Cmod+%5B100%5D%29%5E%7B27%7D+%3D+3%5E%7B27%7D+%5Cmod+%5B100%5D+%3D+87&bg=ffffff&fg=333333&s=0&c=20201002)

![(a \mod [b])^c = a^c \mod [b]](https://s0.wp.com/latex.php?latex=%28a+%5Cmod+%5Bb%5D%29%5Ec+%3D+a%5Ec+%5Cmod+%5Bb%5D&bg=ffffff&fg=333333&s=0&c=20201002)
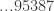
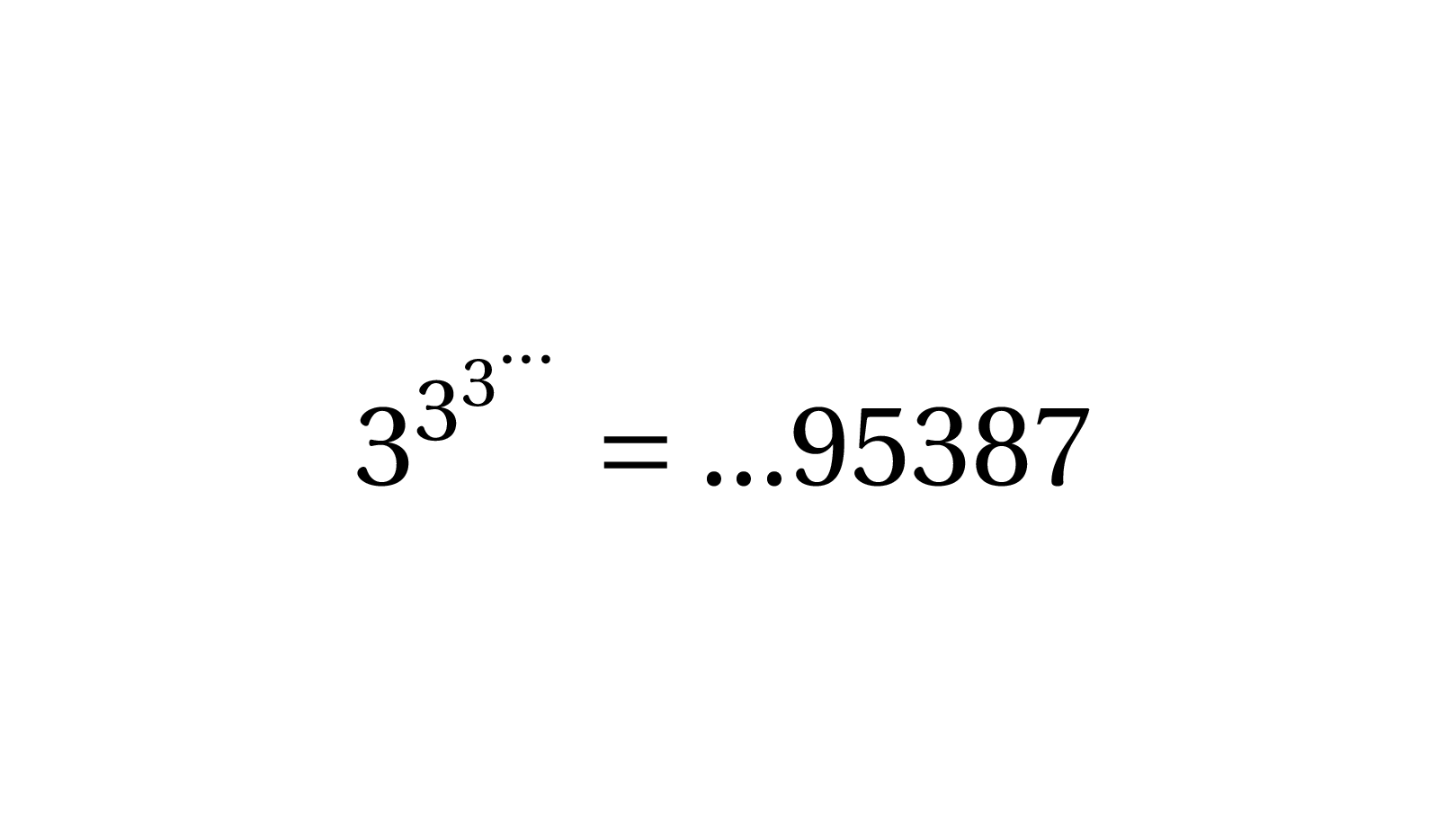 Le seul problème est qu’en pratique le calcul des
Le seul problème est qu’en pratique le calcul des 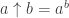 puis
puis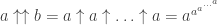
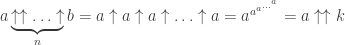

 , s’écrit en fait :
, s’écrit en fait :
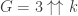 où
où 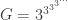
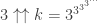 pour quelques valeurs de
pour quelques valeurs de  donc
donc ![3 \uparrow\uparrow 1 \equiv 3 \mod[10]](https://s0.wp.com/latex.php?latex=3+%5Cuparrow%5Cuparrow+1+%5Cequiv+3+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.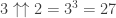 donc
donc ![3 \uparrow\uparrow 2 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3+%5Cuparrow%5Cuparrow+2+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.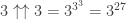 . Le nombre
. Le nombre ![3^{27} = 3^{4 \times 6 + 3} = \left(3^4\right)^6 \times 3^3 \equiv 1^6 \times 3^3 = 27 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B27%7D+%3D+3%5E%7B4+%5Ctimes+6+%2B+3%7D+%3D+%5Cleft%283%5E4%5Cright%29%5E6+%5Ctimes+3%5E3+%5Cequiv+1%5E6+%5Ctimes+3%5E3+%3D+27+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3\uparrow\uparrow 3 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5Cuparrow%5Cuparrow+3+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. . On pourrait faire comme précédemment et essayer d’écrire la division euclidienne de l’exposant
. On pourrait faire comme précédemment et essayer d’écrire la division euclidienne de l’exposant 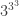 par
par ![3^4 \equiv 1 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E4+%5Cequiv+1+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002) mais ce nombre est un peu trop grand pour cela. Cependant, si on regarde les puissances de
mais ce nombre est un peu trop grand pour cela. Cependant, si on regarde les puissances de ![3^1 =3\equiv 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E1%C2%A0+%3D3%5Cequiv+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^2 = 9 \equiv 1 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E2+%3D+9+%5Cequiv+1+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^3 = 27 \equiv 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E3+%3D+27+%5Cequiv+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^4 = 81 \equiv 1 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E4+%3D+81+%5Cequiv+1+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^5 = 243 \equiv 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E5+%3D+243+%5Cequiv+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^{2p} = \left(3^2\right)^p = 9^p \equiv 1^p = 1 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E%7B2p%7D+%3D+%5Cleft%283%5E2%5Cright%29%5Ep+%3D+9%5Ep+%5Cequiv+1%5Ep+%3D+1+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^{2p+1} = \left(3^2\right)^p \times 3^1 = 9^p \times 3 \equiv 1^p \times 3 = 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E%7B2p%2B1%7D+%3D+%5Cleft%283%5E2%5Cright%29%5Ep+%5Ctimes+3%5E1+%3D+9%5Ep+%5Ctimes+3+%5Cequiv+1%5Ep+%5Ctimes+3+%3D+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3^{n} \equiv 1 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E%7Bn%7D+%5Cequiv+1+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002) et si
et si ![3^{n} \equiv 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E%7Bn%7D+%5Cequiv+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.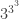 est un nombre impair (ce n’est rien d’autre qu’une puissance de
est un nombre impair (ce n’est rien d’autre qu’une puissance de  ) alors
) alors ![3^{3^{^{3}}} \equiv 3 \mod[4]](https://s0.wp.com/latex.php?latex=3%5E%7B3%5E%7B%5E%7B3%7D%7D%7D+%5Cequiv+3+%5Cmod%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002) c’est-à-dire qu’il est de la forme
c’est-à-dire qu’il est de la forme  . Ainsi,
. Ainsi,![3^{3^{3^{3}}}= 3^{4p+3} = \left({3^4}\right)^p \times 3^3 \equiv 1^p \times 27 = 27 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B3%5E%7B3%5E%7B3%7D%7D%7D%3D+3%5E%7B4p%2B3%7D+%3D+%5Cleft%28%7B3%5E4%7D%5Cright%29%5Ep+%5Ctimes+3%5E3+%5Cequiv+1%5Ep+%5Ctimes+27+%3D+27+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![3\uparrow \uparrow 4= 3^{3^{3^{3}}} \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5Cuparrow+%5Cuparrow+4%3D+3%5E%7B3%5E%7B3%5E%7B3%7D%7D%7D+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.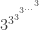 est un nombre impair donc il est de la forme
est un nombre impair donc il est de la forme 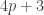 . Si on prend
. Si on prend ![3^{3^{3^{3^{^{3^{\dots^3}}}}}}= 3^{4p+3} = \left({3^4}\right)^p \times 3^3 \equiv 1^p \times 27 = 27 \equiv 7 \mod[10]](https://s0.wp.com/latex.php?latex=3%5E%7B3%5E%7B3%5E%7B3%5E%7B%5E%7B3%5E%7B%5Cdots%5E3%7D%7D%7D%7D%7D%7D%3D+3%5E%7B4p%2B3%7D+%3D+%5Cleft%28%7B3%5E4%7D%5Cright%29%5Ep+%5Ctimes+3%5E3+%5Cequiv+1%5Ep+%5Ctimes+27+%3D+27+%5Cequiv+7+%5Cmod%5B10%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 dès que
dès que 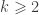 . Comme le nombre de Graham est justement un nombre de la forme
. Comme le nombre de Graham est justement un nombre de la forme 
 à coefficients entiers dont les images des entiers naturels
à coefficients entiers dont les images des entiers naturels 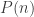 sont souvent des nombres premiers.
sont souvent des nombres premiers.
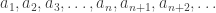 de cette spirale situés sur une même ligne diagonale.
de cette spirale situés sur une même ligne diagonale.
 pour aller, en suivant la spirale, au nombre
pour aller, en suivant la spirale, au nombre 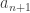 , on parcourra
, on parcourra 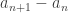 nombres.
nombres.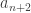 , on parcourra
, on parcourra 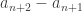 nombres mais on peut aussi dire qu’on parcourra 8 nombres de plus que pour aller de
nombres mais on peut aussi dire qu’on parcourra 8 nombres de plus que pour aller de 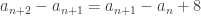
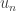 le nombre
le nombre 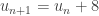 . Autrement dit,
. Autrement dit,  est une suite arithmétique de raison 8, d’où
est une suite arithmétique de raison 8, d’où
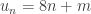 où
où 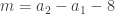 ). Ainsi,
). Ainsi, 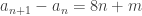 . Par somme télescopique,
. Par somme télescopique,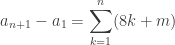
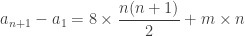
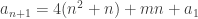
 avec
avec 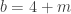 et
et 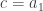
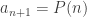 avec
avec 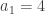 ,
, 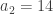 ,
,  ,
, 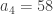 ,… montrée dans la vidéo:
,… montrée dans la vidéo:
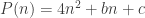 avec
avec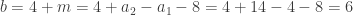
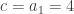
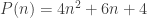 . Vous pouvez vérifier que
. Vous pouvez vérifier que 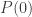 ,
, 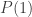 ,
, 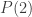 et
et 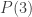 valent respectivement 4, 14, 32 et 58.
valent respectivement 4, 14, 32 et 58.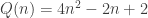 (et non pas
(et non pas 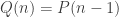 . Autrement dit
. Autrement dit 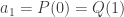 ,
, 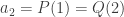 , etc.
, etc.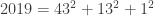
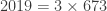 ). Pour être honnête, il n’y a jusque là rien de bien croustillant car 2018 était aussi un nombre semi-premier et que cela se reproduira en 2021. Là où c’est étonnant, c’est que si vous prenez les facteurs premiers de 2019, à savoir 3 et 673, et si vous les concaténez (dans un sens ou dans l’autre) alors vous obtenez encore des nombres premiers car 3673 et 6733 sont aussi des nombres premiers !
). Pour être honnête, il n’y a jusque là rien de bien croustillant car 2018 était aussi un nombre semi-premier et que cela se reproduira en 2021. Là où c’est étonnant, c’est que si vous prenez les facteurs premiers de 2019, à savoir 3 et 673, et si vous les concaténez (dans un sens ou dans l’autre) alors vous obtenez encore des nombres premiers car 3673 et 6733 sont aussi des nombres premiers !
 au départ, le nombre obtenu avec ce processus est
au départ, le nombre obtenu avec ce processus est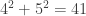 .
.
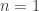 , la somme des carrés des ses (!) chiffres est
, la somme des carrés des ses (!) chiffres est  . Cela veut dire que si on tombe sur le nombre
. Cela veut dire que si on tombe sur le nombre 
 , on obtient successivement les nombres
, on obtient successivement les nombres  ,
,  ,
,  ,
,  ,
, 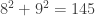 ,
, 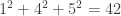 (!),
(!),  et finalement
et finalement 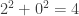 . Autrement dit, si à un moment donné on tombe sur le nombre
. Autrement dit, si à un moment donné on tombe sur le nombre  ,
, 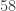 ,
,  ,
, 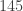 ,
,  ,
, 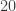 :
:
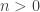 depuis lequel on part, on tombera toujours soit sur 1 (et dans ce cas, à partir d’un moment la suite ne contiendra que des 1), soit sur 4 (et dans ce cas, à partir d’un moment, le cycle 4, 37, 58, 89, 145, 42, 20 se répétera).
depuis lequel on part, on tombera toujours soit sur 1 (et dans ce cas, à partir d’un moment la suite ne contiendra que des 1), soit sur 4 (et dans ce cas, à partir d’un moment, le cycle 4, 37, 58, 89, 145, 42, 20 se répétera).








